前置条件
- 一台带有nvidia 独立显卡的电脑
- 一个操作系统,教程演示使用的是Ubuntu 22.04
搭建过程
- 系统初始化
sudo apt update #更新软件包数据库
sudo apt upgrade # 更新系统
sudo ubuntu-drivers autoinstall # 安装显卡驱动
reboot # 重启
- 安装运行所需的软件
sudo apt install python3.10-venv #补全虚拟环境
sudo apt install git
- 检查显卡支持的cuda版本
nvidia-smi
执行后效果如图:
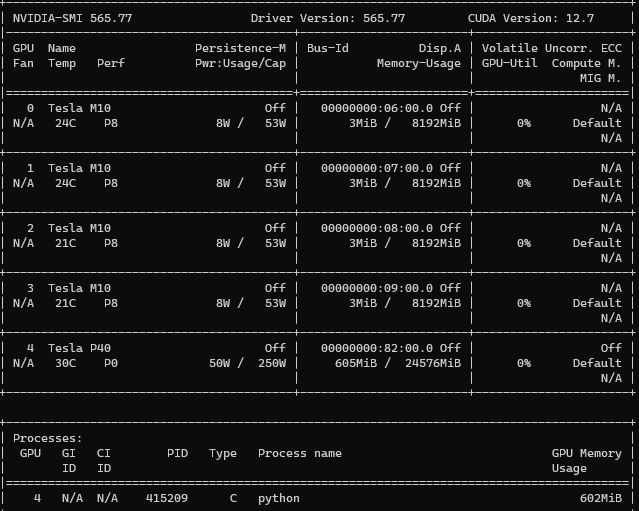
最右边的cuda version 即你的显卡所支持的cuda工具包最高版本
记下这个数字
- 创建虚拟环境
python3 -m venv venv # 第二个"venv"即虚拟环境名称,可以自定义
- 激活虚拟环境
source venv/bin/activate
- 克隆stable diffusion webui 本体
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
#此步骤需要网络环境较好,执行会比较慢,请耐心等待
- 安装stable diffusion 所需的python 依赖
打开
PyTorch
下滑,找到:

如图所示,选择你的操作系统类型,教程使用的是python,所以语言选择python,包管理器选择 pip,只要cuda版本号比你上一步所记下来的版本号小,就可以选择。
PS :越高的cuda版本可能会支持更多的新特性。
以cuda 11.8为例,复制选择后给出的指令,即:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
在刚才激活了虚拟环境内的终端中执行。
等待安装结束。
继续安装剩余依赖:
pip install -r requirements.txt
#如下载速度过慢,可以执行:pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
#将pip切换到速度更快的软件包源
等待安装结束。
- 启动stable diffusion
切换至克隆的stable diffusion webui 项目根目录
cd stable-diffusion-webui
使用你习惯的文本编辑器创建启动脚本,写入如下内容
#!/bin/bash
export COMMANDLINE_ARGS=" --api "
python_cmd="python"
LAUNCH_SCRIPT="launch.py"
"${python_cmd}" "${LAUNCH_SCRIPT}" "$@"
其中 --api 参数表示启用API 访问
赋予此脚本运行权限
sudo chmod +x ./start.sh # start.sh 即脚本文件名
执行此脚本启动stable-diffusion-webui
./start.sh
等待出现 run on http://127.0.0.1:7860 等字样即表示启动成功
可提前将自己想使用的模型放入stable diffusion webui 项目根目录下的models 文件夹中与模型类型所对应的文件夹中
第一次启动,如果未安装模型其会自动下载基础模型加载使用
第一次启动,会自动安装补齐部分依赖,请耐心等待(或换更好的网络 qwq)
