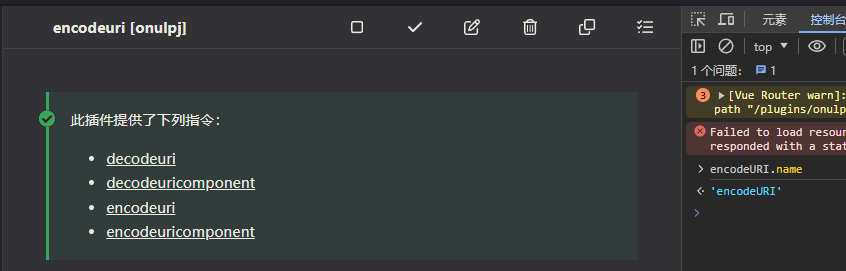
export function apply(ctx: Context) {
const factory = (proccessor: (string) => string) => {
ctx.command(`${proccessor.name} <text:text>`)
.action((argv, text) => {
return proccessor(text)
})
}
[encodeURI, decodeURI, encodeURIComponent, decodeURIComponent].forEach(f=>factory(f))
}
6 个赞
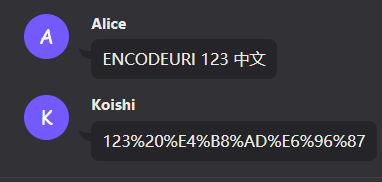
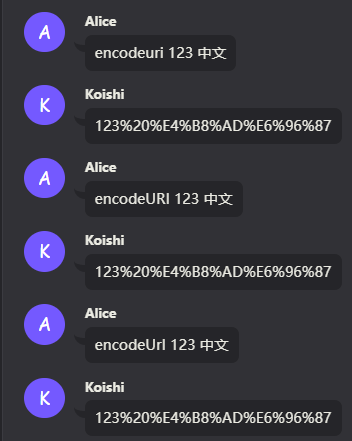
嗯,要不你再试试指令名称是全大写的英文字母,还能不能触发
3 个赞
感觉这东西也没必要严谨。就像quey参数和网站的路径地址一样… 大小写都是不会区分的。
(无论大小写,统一变小写)
2 个赞
原则上是这样
网址的拼写范式(如非必要,都应遵守)是:
统一小写 + 使用短横线(-)分隔
- 不区分大小写是为了避免歧义
- 使用
a-long-word 而不是开发过程中更常见的蛇形 a_long_word 是为了最后的呈现效果:网址变成“超链接”(准备好给人识别并点击跳转)后,国际惯例默认会将超链接文本全部添加下划线,用蛇形写法的话(在很多字体下)就会难以辨认
但实际上还是有很多拒绝遵循这个规范的奇葩
而且也未必是人家做错了,本质还是个取舍(易用性 & 功能性)问题
比如短链接服务:假设最终生成的短网址里用来区分的标识符是 7 位,不区分大小写只有 (26 + 10)^7 的容量,区分大小写才会有 (26 + 26 + 10)^7的容量
又比如 query 参数:?ip=127.0.0.1&user=admin&flag=NO_TOKEN
URI 参数内容 取决于 通信双方的业务逻辑 怎么写的,他就要那样写(区分大小写 + 使用下划线)你又有什么办法
还有很多 RESTful 的 API 设计,也是直接让 path 区分大小写来描述具体资源的(比如 GET /UserInfo/123;当然,更正确的设计是 GET /user/info/123)
另外我发现 .NET 做的网站似乎也很喜欢这样玩(当然现在已经很少见了)
4 个赞
ilharp
10
个人感觉用 dash 的原因还是因为这样可以同时满足 RFC 1123 和 RFC 1035。RFC 1035 在 RFC 1123 的基础上规定必须以字母开头。这样的字段可以位于大多数远程协议的任何位置,比如子域名。
下划线则多是用于满足代码内的变量要求,如 Satori。
2 个赞